Scaling past 1 million ELF symbol relocations
Published 2024-07-21 on Farid Zakaria's Blog
Note
This is a follow up to my previous post on speeding up elf relocations for store based systems.
I wrote earlier about some impressive speedups that can be achieved by foregoing the typical dynamic linking that can be applied to systems such as Nix where the dependencies for a given application are static.
The first attempt at memoization ELF symbol relocations involved strcmp on the shared library name.
The code would memoize the relocations into entries such as the one below.
{
"type": 6,
"addend": 0,
"st_value": 16392,
"st_size": 4,
"offset": 16368,
"symbol_name": "global_variable",
"symbol_dso_name": "/nix/store/fni9dgkmimqi54q308zi37ycpfx5mq54-libfoo/lib/libfoo.so",
"dso_name": "/nix/store/6xqcsfhh1pk6s9cib8lkp5k9ybf05sq7-patched_hello_world/bin/hello_world"
}
For each entry, the appropriate struct dso pointer would be located by strcmp.
static struct dso *find_dso(struct dso *dso, const char *name) {
for (; dso; dso=dso->next) {
if (strcmp(dso->name, name) == 0) {
return dso;
}
}
return NULL;
}
🙄 Of course this is non-optimal and is θ(nm); but I wanted to prove that it would work first.
Now that I’ve proven efficacy, I began optimizing the lookups.
A small-trick I was able to leverage was that the linked list produced by the dynamic linker must be deterministic in order; otherwise symbol interposition (shadowing) could be varied across invocations.
I was able to store the index into the linked list rather than the name itself to find the struct dso.
{
"symbol_dso_index": 1,
"dso_index": 0,
}
static struct dso *find_dso(struct dso *app, size_t index) {
while (index > 0) {
app = app->next;
index--;
}
return app;
}
This brought the lookup to θ(n) – can we do better?
Turns out we can get to θ(k) (constant time), if we are willing to pay one-time cost of converting the linked list to an array for index-based access.
We iterate the array once to discover the size of the array and then leverage VLA, variable length arrays, to allocate a dynamic array onto the stack.
static void make_dso_table(struct dso *app, struct dso **dso_table)
{
size_t count = 0;
while (app) {
dso_table[count++] = app;
app = app->next;
}
}
static size_t number_of_dso(struct dso *app)
{
size_t count = 0;
while (app) {
count++;
app = app->next;
}
return count;
}
static void reloc_symbols_from_cache(struct dso *app,
const CachedRelocInfo * info,
size_t reloc_count)
{
size_t number_of_dsos = number_of_dso(app);
struct dso * dso_table[number_of_dsos];
make_dso_table(app, dso_table);
Do these optimization make a difference in practice, especially given how much time is spent on dynamic linking? 🤔
Turns out for sufficiently large number of symbol relocations distributed over multiple shared libraries, we can see even more drastic results.
On a synthetic benchmark, creating 1000 shared objects each with 1000 symbols for a total of 1_000_000 (million) total relocations can see speedups as large as 18-22x.
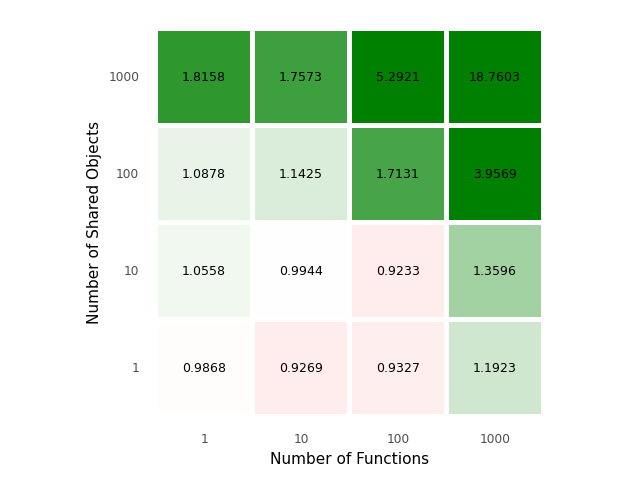
A noticeable speedup was seen in the established benchmark pynamic. Pynamic is a benchmark written by Lawrence Livermore National Laboratory (LLNL) to simulate internal software written.
Similar to the prior synthetic benchmark, Pynamic creates an MPI application which starts an embedded Python interpreter and links it against a desired amount of Python modules.
Running the same configuration as outlined in documentation written by LLNL shows speedups as large as 8x (3.672 secs ± 0.084 vs. 26.152 secs ± 0.095). 🏎️
Finding real world applications beyond the software Pynamic itself may be emulating which contain 1_000_000+ symbol relocations proved challenging; but seeing the time needed to perform the relocations (26 seconds) it is understandable.
Ulrich Drepper (long time glibc author) in fact devotes a large section of his guide on How to Write Shared Libraries. Portions of the advice centers around shortening symbol names and being judicious about which symbols are exported to minimize the number of symbol relocations created. This optimization technique eschews much of that advice and allows applications to scale beyond traditional limits and still appear relatively responsive in startup.
Similar to the C10K problem faced in the earlier 2000s as the Linux kernel was attempting to scale to 10_000 connections; this work allows applications to think about scaling to 1 million symbol relocations.
Go forth and link.
Improve this page @ cf0dfdb
The content for this site is
CC-BY-SA.