Huge binaries: I thunk therefore I am
Published 2025-12-29 on Farid Zakaria's Blog
In my previous post, we looked at the “sound barrier” of x86_64 linking: the 32-bit relative CALL instruction and how it can result in relocation overflows. Changing the code-model to -mcmodel=large fixes the issue but at the cost of “instruction bloat” and likely a performance penalty although I had failed to demonstrate it via a benchmark 🥲.
Surely there are other interesting solutions? 🤓
First off, probably the simplest solution is to not statically build your code and rely on dynamic libraries 🙃. This is what most “normal” software-shops and the world does; as a result this hasn’t been such an issue otherwise.
This of course has its own downsides and performance implications which I’ve written about and produced solutions for (i.e., Shrinkwrap & MATR) via my doctorate research. Beyond the performance penalty induced by having thousands of shared-libraries, you lose the simplicity of single-file deployments.
A more advanced set of optimizations are under the umbrella of “LTO”; Link Time Optimizations. The linker at the final stage has all the information necessary to perform a variety of optimizations such as code inlining and tree-shaking. That would seem like a good fit except these huge binaries would need an enormous amount of RAM to perform LTO and cause build speeds to go to a crawl.
Tip This is still an active area of research and Google has authored ThinLTO. Facebook has its own set of profile guided LTO optimizations as well via Bolt.
What if I told you that you could keep your code in the fast, 5-byte small code-model, even if your binary is 25GiB for most callsites. 🧐
Turns out there is prior art for “Linker Thunks” [ref] within LLVM for various architectures – notably missing for x86_64 with a quote:
“i386 and x86-64 don’t need thunks” [ref]
What is a “thunk” ?
You might know it by a different name and we use them all the time for dynamic-linking in fact; a trampoline via the procedure linkage table (PLT).
A thunk (or trampoline) is a linker-inserted shim that lives within the immediate reach of the caller. The caller branches to the thunk using a standard relative jump, and the thunk then performs an absolute indirect jump to the final destination.
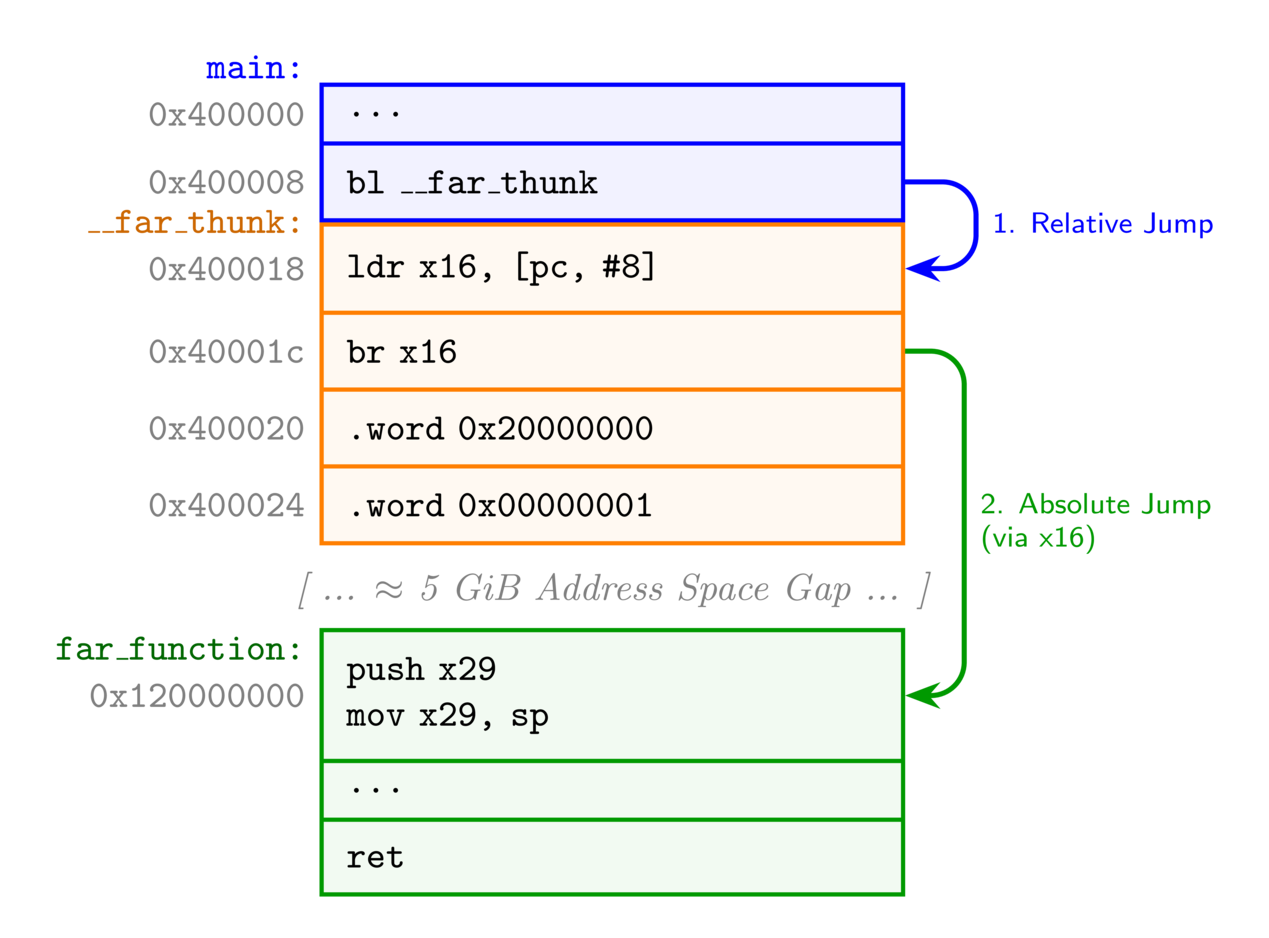
LLVM includes support for inserting thunks for certain architectures such as AArch64 because it is a fixed-size instruction set (32-bit), so the relative branch instruction is restricted to 128MiB. As this limit is so low, lld has support for thunks out of the box.
If we cross-compile our “far function” example for AArch64 using the same linker script to synthetically place it far away to trigger the need for a thunk, the linker magic becomes visible immediately.
> aarch64-linux-gnu-gcc -c main.c -o main.o \
-fno-exceptions -fno-unwind-tables \
-fno-asynchronous-unwind-tables
> aarch64-linux-gnu-gcc -c far.c -o far.o \
-fno-exceptions -fno-unwind-tables \
-fno-asynchronous-unwind-tables
> ld.lld main.o far.o -T overflow.lds -o thunk-aarch64
We can now see the generated code with objdump.
> aarch64-unknown-linux-gnu-objdump -dr thunk-example
Disassembly of section .text:
0000000000400000 <main>:
400000: a9bf7bfd stp x29, x30, [sp, #-16]!
400004: 910003fd mov x29, sp
400008: 94000004 bl 400018 <__AArch64AbsLongThunk_far_function>
40000c: 52800000 mov w0, #0x0 // #0
400010: a8c17bfd ldp x29, x30, [sp], #16
400014: d65f03c0 ret
0000000000400018 <__AArch64AbsLongThunk_far_function>:
400018: 58000050 ldr x16, 400020 <__AArch64AbsLongThunk_far_function+0x8>
40001c: d61f0200 br x16
400020: 20000000 .word 0x20000000
400024: 00000001 .word 0x00000001
Disassembly of section .text.far:
0000000120000000 <far_function>:
120000000: d503201f nop
120000004: d65f03c0 ret
Instead of branching to far_function at 0x120000000, it branches to a generated thunk at 0x400018 (only 16 bytes away). The thunk similar to the large code-model, loads x16 with the absolute address, stored in the .word, and then performs an absolute jump (br).
What if x86_64 supported this? Can we now go beyond 2GiB? 🤯
There would be some more similar thunks that would need to be fixed beyond CALL instructions. Although we are mostly using static binaries, some libraries such as glibc may be dynamically loaded. The access to the methods from these shared libraries are through the GOT, Global Offset Table, which gives the address to the PLT (which is itself a thunk 🤯).
The GOT addresses are also loaded via a relative offset so they will need to changed to be either use thunks or perhaps multiple GOT sections; which also has prior art for other architectures such as MIPS [ref].
With this information, the necessity of code-models feels unecessary. Why trigger the cost for every callsite when we can do-so piecemeal as necessary with the opportunity to use profiles to guide us on which methods to migrate to thunks.
Furthermore, if our binaries are already tens of gigabytes, clearly size for us is not an issue. We can duplicate GOT entries, at the cost of even larger binaries, to reduce the need for even more thunks for the PLT jmp.
What do you think? Let’s collaborate.
Improve this page @ 3634e47
The content for this site is
CC-BY-SA.