hjar.
🤨
WTF is an hjar ?
☝️ It is the newer version of ijar !
😠
WTF is an ijar ?
Let’s discover what an ijar (Interface JAR) is and how it’s the magic sauce that makes Bazel so fast for Java.
Let’s consider a simple Makefile
program: main.o utils.o
$(CC) -o program main.o utils.o
main.o: main.c utils.h
$(CC) -c main.c
utils.o: utils.c utils.h
$(CC) -c utils.c
We’ve been taught to make use of header files, especially in C/C++ so that we can avoid recompilation as a form of early cutoff optimization.
☝️ If we change utils.c solely, we do not have to recompile main.o.
We can visualize this Makefile in the following graph.

Ok, great! What does this have to do with Java & Bazel ?
Well, let’s remember back to my previous post on reproducible outputs.
Bazel constructs a similar graph to determine when to do early cutoff optimization through the “Action Key”. Bazel computes a hash for each action, that takes dependencies for instance, and if the hash hasn’t changed it can memoize the work.
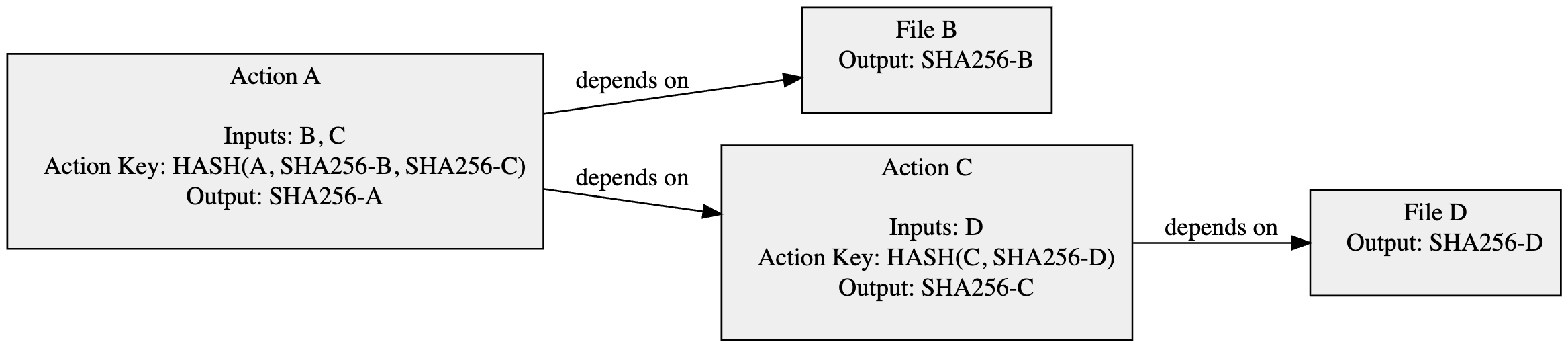
In Java-world, dependencies are expressed as JARs.
Wouldn’t private-only changes to a dependency (i.e. renaming a private variable) cause the Action Key HASH to change (since it produced a different JAR) ?
🤓 YES! That is why we need an ijar !
ijar is a tool found within the Bazel repository bazel/third_party/ijar.
You can build and run it fairly simple with Bazel
$ bazel run //third_party/ijar
Usage: ijar [-v] [--[no]strip_jar] [--target label label] [--injecting_rule_kind kind] x.jar [x_interface.j
ar>]
Creates an interface jar from the specified jar file.
It’s purpose is straightforward. The tool strips all non-public information from the JAR. For example, it throws away:
- Files whose name does not end in “.class”.
- All executable method code.
- All private methods and fields.
- All constants and attributes except the minimal set necessary to describe the class interface.
- All debugging information (LineNumberTable, SourceFile, LocalVariableTables attributes).
The end result is something in spirit to a C/C++ header file.
Let’s see it in practice. 🕵️
Let’s now create an incredibly simple JAR. It will have a single class file within it.
public class Banana {
public void peel() {
System.out.println("Peeling the banana...");
squish();
}
private void squish() {
System.out.println("Squish! The banana got squashed.");
}
}
We compile it like usual.
$ javac Banana.java
$ jar cf banana.jar Banana.class
When we run ijar on it we get the hash e18e0ae82bdc4deb04f04aa
⚠️ I shortened the hashes to make them more legible.
$ bazel-bin/third_party/ijar/ijar banana.jar
$ sha256sum banana.jar
f813749013ea6aba2e00876 banana.jar
$ sha256sum banana-interface.jar
e18e0ae82bdc4deb04f04aa banana-interface.jar
Let’s now change the internals of the Banana class; let’s rename the method squish() -> squash().
Let’s recompute the new sha256.
$ sha256sum banana.jar
9278282827ddb55c68eb370 banana.jar
$ sha256sum banana-interface.jar
e18e0ae82bdc4deb04f04aa banana-interface.jar
🤯 Although the hash of banana.jar had changed, we still get e18e0ae82bdc4deb04f04aa for the ijar.
We now the equivalent of a header file for Java code. 🙌
Bazel will use the ijar when computing the Action Key hash in lieu of the JAR for the dependencies you may depend on; thus avoiding costly rebuilds when only private information changes within your dependency.
This is the amazing lesser known tool that makes Bazel super-powered 🦸 for JVM languages.
]]>